

推荐导读
随着 DeepSeek 的迅速走红,大模型的应用再度迎来一轮迅猛发展。身为拥有技术背景的团队,上午刚在思索如何 DIY VS Code 接入 DS 的方案,下午 MarsCode 直接更新支持了 DS 模型切换。
鉴于此,我们决定在 2025 年摒弃在“搭轮子”方面投入精力,转而专注于“AI 普惠”,例如在个人知识管理、团队 Idea 管理以及公司管理方面发挥 AI 的辅助作用。
未来,那些 AI 工具研发者将凭借自身的 AI 工具和思维,更为迅速地创造出更优质的 AI 工具。并且,这部分工作将由更少的人负责,而更多的人则需适应 AI 带来的益处,同时也要应对 AI 对人类文化、政治以及信仰所带来的冲击。
本周,我们将大量内部知识、想法及知识导入 Atlassian Cloud 平台,围绕 Jira + Rovo 重新构建内部的项目管理体系,将更多传统 PM 的职责直接交由 AI 处理,使我们原本资深的 PM 顾问转变为客户的“策略顾问”和“领域专家”。
作为全球领先且市值最高的“项目管理与协作软件”平台公司,Atlassian (Jira)公司近期披露了自己的“Hybrid LLM”方案。若你认为自己是天选之子,想要搭建自己的知识 AI 体系,可予以参考。
原作者:Steven Yoo(Atlassian Senior Principal Engineer)整理:填空题咨询
原标题:Enhancing Rovo Chat with Hybrid LLM Approach
AI应用介绍
Rovo Chat 是一款 AI 驱动的助手,旨在通过简单的聊天界面提高生产力并释放创造力。通过利用 GPT、Claude、Gemini、Mistral 和 LLaMA 等高级大型语言模型 (LLM) 的组合,Rovo Chat 改变了企业与信息交互的方式,使其更易于访问和作。该平台提供三个关键功能:
企业 Q&A:使用企业搜索进行开放域问答,包括跨所有工作场所应用程序(如 Jira、Confluence、Atlas、Google Docs、Sharepoint 等)的数据。
内容消费:帮助用户高效消费内容。例如,“列出此页面中的行动项”
内容创建:帮助撰写草稿或润色提供的草稿。这利用了固有的强大 LLM 功能。例如,“写我过去一个季度的自我评论”
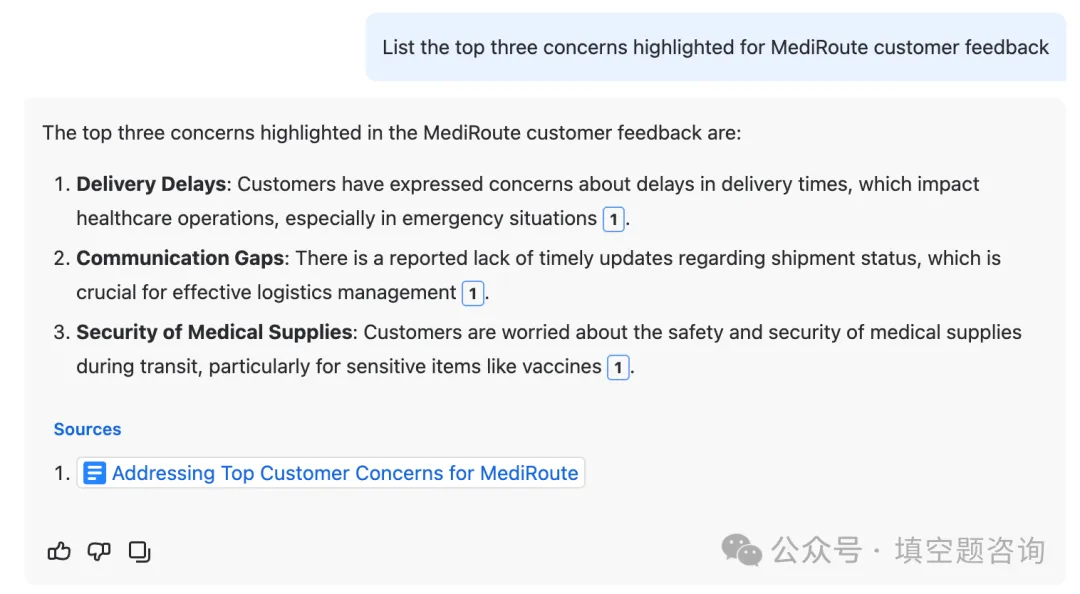
使用混合 LLM 方法优化性能
Rovo Chat 利用混合 LLM 方法来优化质量、延迟和成本。接下来,我们将介绍如何制定每个问题并为每个任务选择最佳 LLM。
Query Rewriting 查询重写
问题:在对话式聊天机器人中,用户查询通常需要优化才能由底层搜索引擎有效处理。我们利用了 Atlassian 的文档搜索引擎,该引擎可扩展至数亿用户。
解决方案:我们执行两个阶段的查询重写:
- Semantic query 语义查询:给定对话历史、用户上下文和当前查询,我们生成一个
semantic query,该查询会删除不必要的内容,从任何先前的对话回合中添加上下文(例如,共指解析),并注入任何隐含的用户上下文(例如位置、公司、时间)。 - Keywords queries 键字查询:给定生成的
semantic query,我们创建多个简短的关键字查询,以最大限度地提高文档召回率。
我们通过多种方式优化查询:
- 概括过于具体的问题,例如“我可以带狗来办公室吗” -> “办公室宠物政策”
- 将复杂查询分解为多个简单查询,例如:“Q2 收益和 Q3 收益有什么区别” -> “Q2 收益”, “Q3 收益”
- 使用同义词和附加用户上下文扩展单个查询,例如:我如何获得悉尼签证”-> “悉尼签证申请”, “澳大利亚签证申请”, “<用户所在国家的悉尼签证要求>”</用户所在国家的悉尼签证要求>
我们已经看到,内部搜索 Q&A 查询集的查询优化实现了更高的答案精度 (+10%) 和更快的延迟 (-17%)。
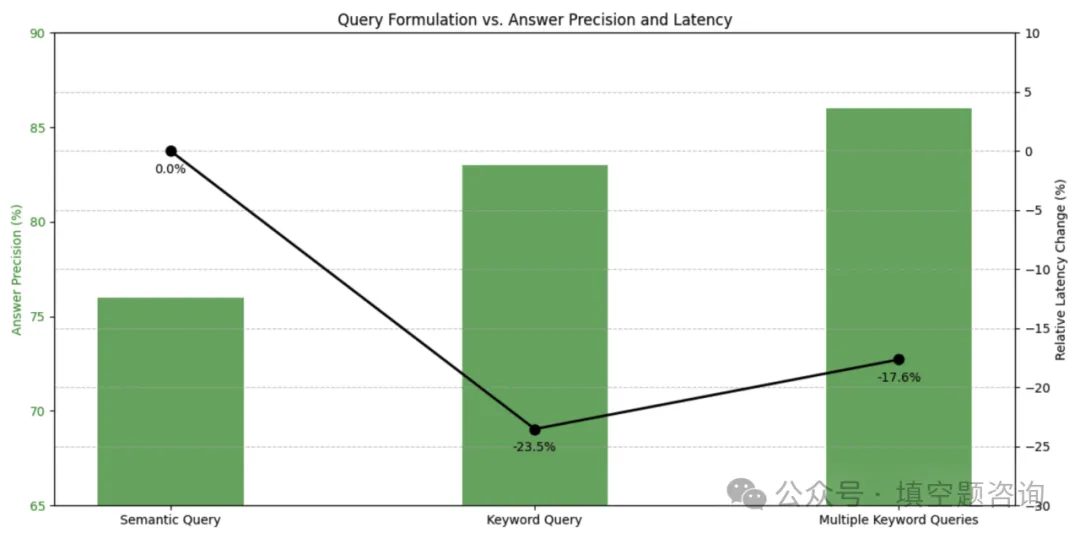
对于较简单问题,像 LLaMA-3 8B 这样的小型语言模型表现同样出色,与大型语言模型相比,它更便宜且速度更快。我们从一个大型模型开始,逐渐转向更小的模型,同时文档召回率的提升得以保持。
在每个步骤中,我们对每个模型进行提示微调以匹配召回率。除了召回数字之外,查看来自我们内部试用的数百个重写查询最为有用,因为对于工程师来说,很容易扫描简短的关键字查询,并查看每个模型的输出是否与更大的模型传达相同的语义。
Accurate Information Retrieval through Multiple Plugin Routing
通过多个插件路由进行准确的信息检索
问题:当用户的意图不明确时,LLM 的函数调用无法可靠地工作。给定用户问题和可用插件 (函数) 列表,决定调用哪些插件来检索必要的信息来回答用户的问题。
企业数据以结构化和非结构化形式(例如,关系数据库、搜索索引、键值存储)存储在不同的位置,涵盖 Jira、Confluence、Atlas、Google Docs、Sharepoint、Slack、User Profile Service、Teamwork Graph 等产品和服务。要回答用户的问题,通常需要 Rovo Chat 查找多个位置,以确定是否可以回答用户的问题。LLM 模型通常会选择一个数据源,并尝试根据naive RAG中不完整或不相关的信息来回答。
以下是一组示例插件:
- Search-QA-Plugin从 Jira、Confluence、Atlas 等工作场所应用程序,以及 Google Docs、Sharepoint 等连接的第三方产品中检索相关段落。
- Content-Read-Plugin检索给定 URL 的内容。
- Jira-JQL-Plugin使用 JQL(Jira 查询语言)根据一组筛选器搜索 Jira 问题,支持结构化查询。
- People-Plugin查找人员的个人资料信息、最近的活动及其密切协作者。
- Page-Search-Plugin使用 CQL (Confluence Query Language) 查找 Confluence 页面或博客文章,支持结构化查询。
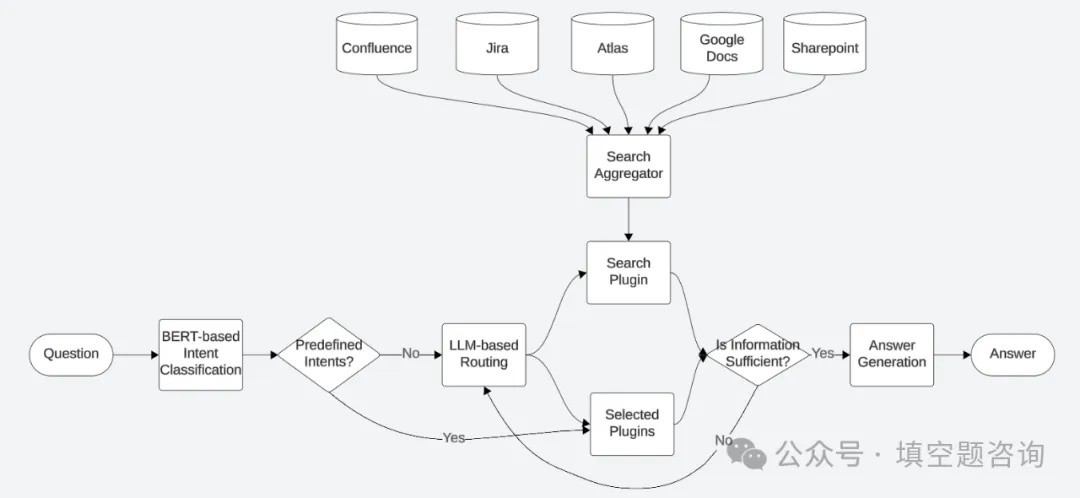
解决方案:我们围绕 LLM 的函数调用进行了更多的编排,以增加从不同数据源检索用户问题相关信息的机会。
- 基于 BERT 的意图分类器:我们为简单和频繁的意图(例如,问题是否与当前浏览页面有关)训练了二进制意图分类器,以实现更快的延迟和更高的准确性。我们使用内部 dogfaging 查询为训练数据设定了种子,并使用 LLM 生成了 100K 训练数据。
- 并行搜索:在查找其他数据源的同时点击搜索索引,因为搜索索引是最大的信息来源。
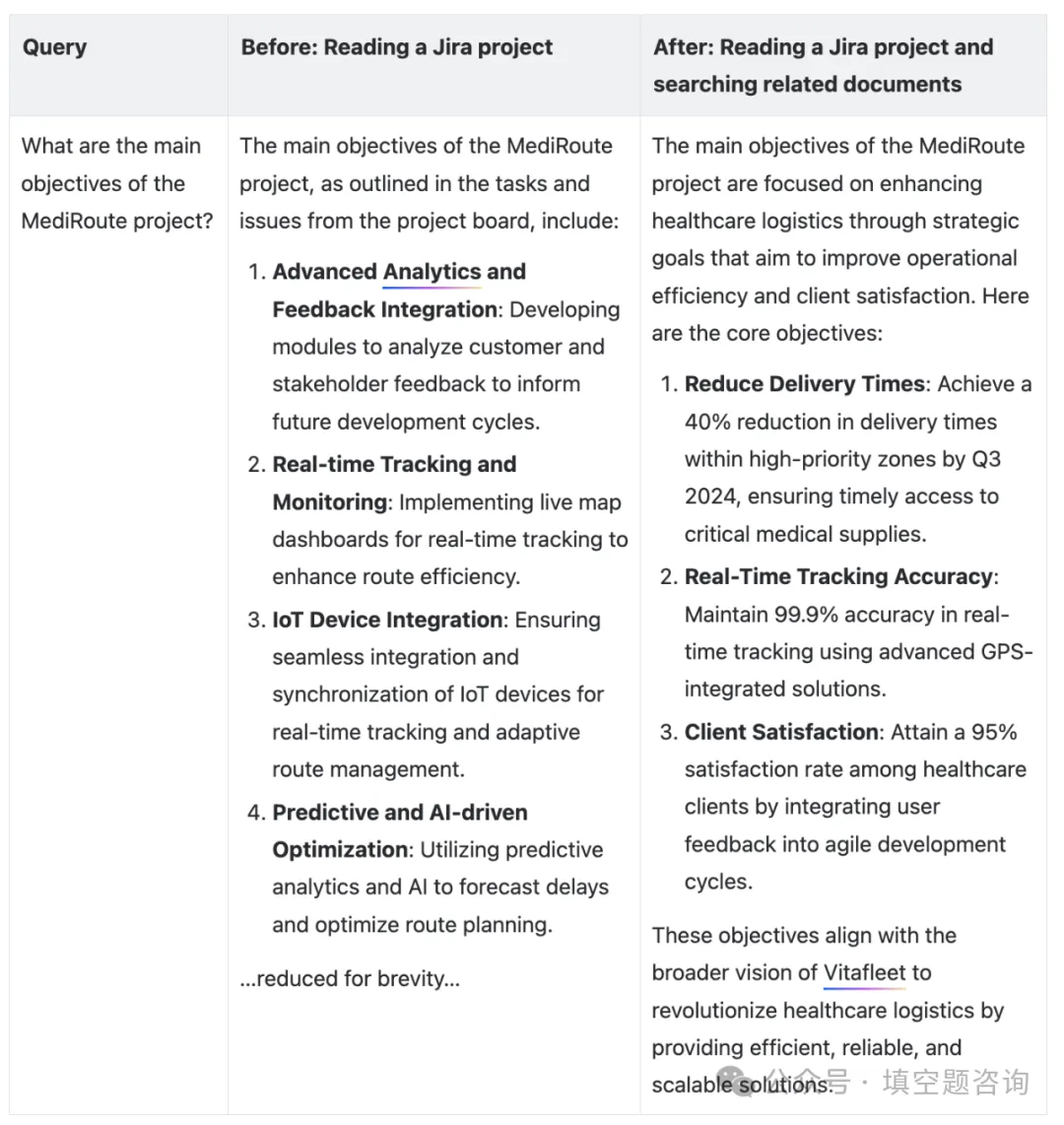
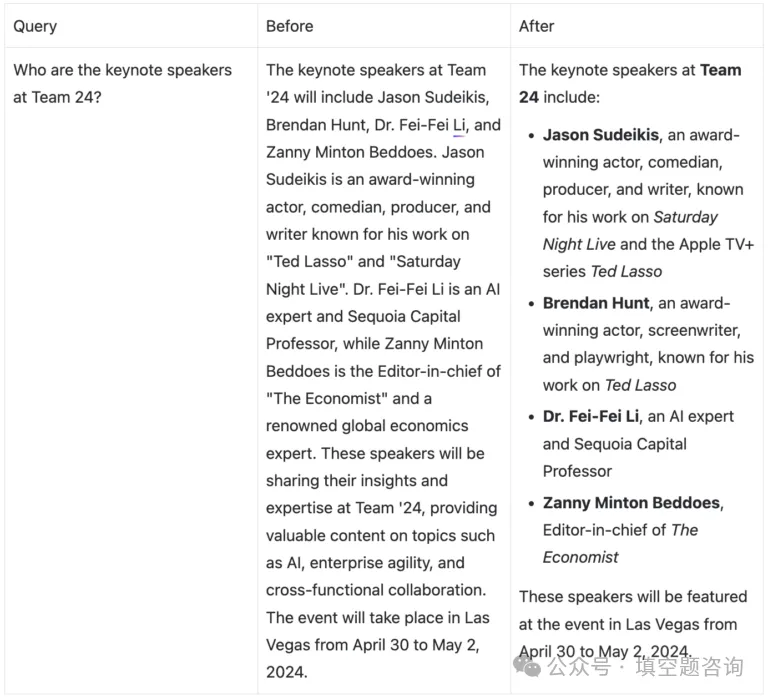
以下示例显示了 Rovo 聊天的多个插件路由的好处。通过应用多个插件路由,Rovo Chat 总结了项目的核心目标,而不是详细列举了 Jira 任务。
我们针对来自内部数据的 226 个查询的基准,评估了多函数调用任务的 10 个不同的 LLM。正确的插件是人工注释的,并且它们可以是多个插件。选择任何正确的插件都会被标记为正确。我们已经尝试了原生函数调用以及内部的 react prompt。插件准确率在基准测试中从 73.1% ~ 94.2% 不等,我们使用准确率最高的模型。随着 LLM 在多个功能上变得更强大,并且我们添加了更多功能,我们会不断评估新的 LLM 并切换到性能最佳的模型。
通过 Plugin Helpness Verification 确保相关性
问题:即使选择了正确的插件并提供了正确的参数,底层组件也可能犯了错误。搜索引擎可能会返回不相关的信息,或者实体链接服务可能无法将人员名称“Steven”连接到团队工作图中的正确实体。当检索到不相关的信息时,LLM 可能会生成错误的答案。
解决方案:我们放置了一个 SLM(小语言模型)来检查检索到的信息是否与用户的问题相关,然后再将其输入到 LLM 中以生成答案。我们试验了 3 种不同的 SLM,对于包含 91 个查询的内部人工注释数据集,它们的准确率在 88% ~ 98.9% 之间。
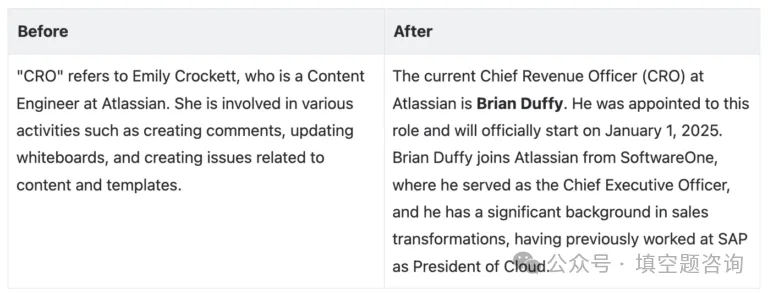
以下是 Rovo Chat 在插件有用性检查前后对“谁是 CRO”问题的回答的说明性示例。
Generating Accurate and Contextual Responses
生成准确的上下文响应
问题:给定收集的企业信息,生成准确且与上下文相关的答案。这就是最强大的 LLM 可以展示其力量的问题。
对于测量,我们从内部数据 创建了一个评估集;~241 个查询,由三个场景组成:企业 Q&A、内容使用和内容生成。数据集的格式为 (query, user context, plugin outputs, ground truth answer)。在开发 Rovo Chat 时,我们从早期版本的正确答案(由人类标记)或人类编写的真实答案中迭代收集了真实答案。它包含正面和负面示例。
- 正面示例(83%,199/241 个查询):插件输出包含足够的信息来回答用户的问题,并且 LLM 应回答在语义上类似于真实答案的响应。
- 负面示例(17%,42/241 个查询):插件输出不包含足够的信息来回答用户的问题,并且预计 LLM 不会回答,而是使用其内部知识来回答问题。
解决方案:我们评估了 6 种不同的 LLM,它们在这项任务中达到了 93.7% ~ 81.3% 的准确率。请注意,我们在此评估中冻结了插件输出,以将答案生成任务的测量与函数调用和检索精度隔离开来。我们观察到,业内更新、更强大的模型通常优于以前的版本,因此我们一直在不断测试,并在更强大的模型可用时切换到它们。
自动提示调整:我们实施了自动提示调整,以迭代优化提示,确保响应易于阅读且与上下文相关。此过程涉及使用本文中描述的技术来提高生成答案的质量。我们审查了团队成员生成的查询和答案,并使用判断来微调提示,确保生成的答案与人类的期望密切相关且易于理解。
Assessing Rovo Chat Quality with a LLM Judge
与 LLM Judge一起评估 Rovo 聊天质量
问题:评估 LLM 生成的响应质量可能具有挑战性,因为它们很长。基于计算的方法,如 BLEU、ROUGE、BERT 分数,对参考答案高度敏感。人工评估速度慢,而且频繁重复的成本很高。进行高质量的评估对于确保 Rovo Chat 在每个版本上不断改进至关重要。
解决方案:为了对 Rovo Chat 的质量进行可扩展的衡量,我们使用 LLM Judge。任务是判断 Rovo Chat 的响应在语义上是否与用户问题的参考答案相似。与使用分数范围相比,这种二进制标记简化了对人类和 LLM 评估者的评估,其中分数的校准成为另一个需要解决的问题。
- 输入:(用户问题、参考答案、Rovo Chat 响应)
- LLM Judge的输出:(对齐、正确或错误)
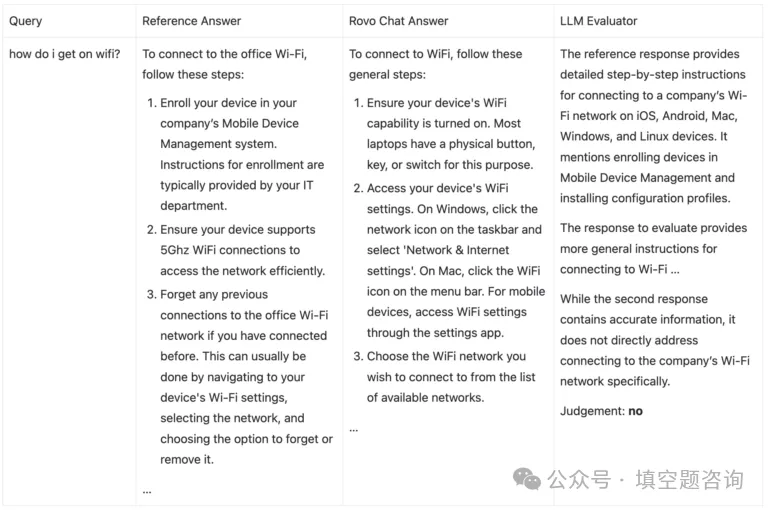
为了进行测量,我们从内部员工那里收集了 ~800 个问答对。这是一个参考依赖评估的说明性示例,其中用户问“我如何开始使用 wifi?虽然 Rovo Chat 的答案回答了一般如何连接到 Wifi,但企业用户询问的是他们的公司网络连接,因此 LLM 法官将 Rovo Chat 的答案标记为不正确。即使对于没有参考答案的人来说,这也很难判断。
我们还通过比较人类和 LLM 判断之间的重叠判断来判断 LLM 判断的质量。我们评估了 6 种不同的 LLM,它们与人类判断的一致性从 79% 到 95% 不等,并使用了重叠程度最高的模型。最好的模型仍然与人类判断有 5% 的差异,但这是一个可以接受的噪音,因为即使是人类也不会 100% 一致。
结论
我们混合使用了 LLM 来优化质量,同时在构建 Rovo Chat 时将延迟和成本保持在合理的水平。这种战略方法使 Rovo Chat 能够提供精确且与上下文相关的答案,从而增强用户体验和生产力。通过利用自动提示调整,我们改进了系统生成易于阅读的响应的能力,确保用户收到准确且可访问的信息。
Gen AI 领域正在快速发展。我们将继续将 LLM 的最新进展集成到 Rovo Chat 中,通过处理更复杂的查询和高度上下文化的问题来提高用户的工作效率。我们将继续在每一个环节进行衡量,以便为用户提供最佳体验。
Comments are closed