

从 RAG 到 Context Graph :AI 需要理解「组织如何运作」
本文属于《AI Context Engineering》系列。本篇聚焦 Context Graph 的技术演进脉络与行业企业实践,以调研视角梳理主要玩家的路径差异,供关注企业 AI 基础设施的读者参考。
为什么 RAG 会“答非所问”?
过去两年,几乎所有企业 AI 项目都绕不开 RAG(检索增强生成)。它简单、有效,是连接大模型与私有知识的入门级方案。
但随着企业把 AI 从”问答助手”推向”业务决策”和”Agent 自主执行”,一个问题越来越尖锐:
AI 能找到文档,但不理解组织。
它不知道谁在负责这件事,哪个结论已经过时,哪次讨论才是最终决定,哪个 PR 已经回滚,当前团队目标是什么,哪个 incident 正在发生,哪些人经常协作,哪些数据可信。
于是 AI 会幻觉、会上下文错乱、会给出”技术上正确但组织上荒谬“的答案。
这不是模型能力的问题,而是上下文结构的问题。
行业正在形成一个共识:AI 的下一层基础设施,不是更大的模型,而是更好的上下文。而承载这个上下文的技术形态,越来越多地指向同一个方向——Context Graph(上下文图谱)。
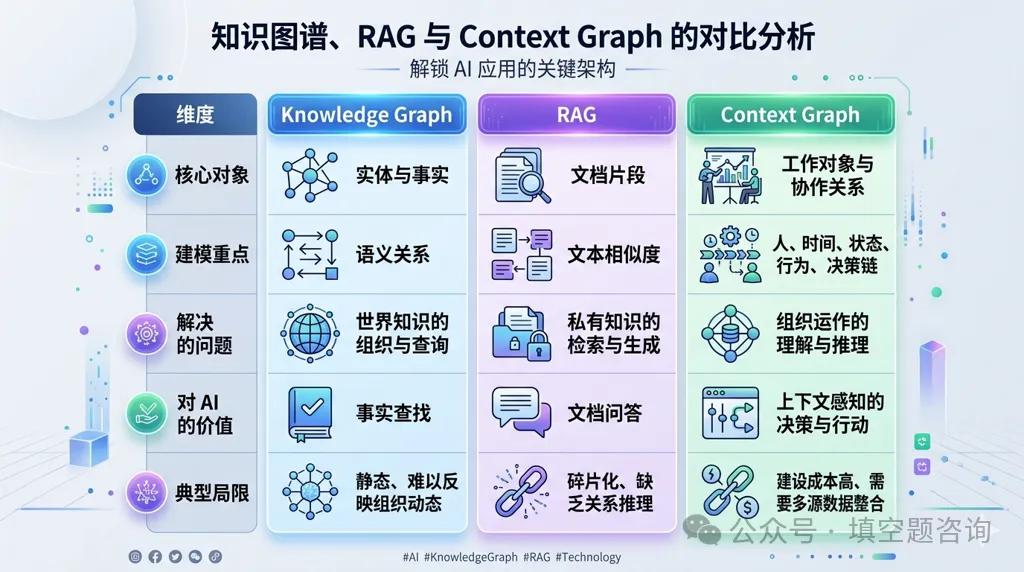
RAG 的优点与天生短板
1)RAG的底层逻辑
将文档拆分为文本片段→向量化入库→提问时检索相似片段→交给大模型生成回答。
2)RAG的核心优势
- 低成本连接私有知识,弥补大模型知识滞后与基础幻觉。
- 部署简单、见效快,是企业级智能问答的入门级标配。
3)RAG的结构性瓶颈
- 只有相似度,没有“实体-关系”语义,难以理解业务逻辑。
- 检索结果碎片化,难以支撑多跳、跨链路的复杂推理。
- 证据链薄弱、可解释性差,难以满足合规与审计。
- 难承载AI Agent的长期记忆、流程追溯与业务级决策。
什么是 Context Graph 上下文图谱?
不止是“知识图谱(Knowledge Graph)”。它将实体、关系与业务上下文(时序、流程、状态、规则、决策链路)统一建模,形成可计算、可追溯、可执行的全景关系网络。
它真正建模的不是”世界有什么知识”,而是”组织如何运作“,这是一个关键的范式转移:从”知识组织”转向”工作上下文编排(work context orchestration)”。
- 节点(Entity):人物、公司、产品、事件、流程、系统、工单等。
- 边(Relation):收购、合作、审批、从属、依赖、因果、触发、阻塞等。
- 上下文(Context):时间线、状态变迁、业务规则、责任与权限、数据口径、历史决策与评审记录。
核心价值
- 支持多跳与链式推理,复杂问题精准作答。
- 答案自带证据链,可溯源、可解释,满足合规审计。
- 打通分散信息,还原事件与决策全链路。
- 为AI Agent提供长期记忆、策略规划与任务编排的“语义操作系统”。
一句话总结:RAG解决“有知识可用”,Context Graph解决“懂逻辑、能推理、可决策”。
为什么现在 Context Graph 突然变得关键
Context Graph 并不是新概念,但它在 2024-2025 年突然成为行业焦点,背后有三股力量在推动。
1)模型能力趋同,上下文成为差异化变量
当 GPT-4、Claude、Gemini、Llama 等主流模型在基础能力上日益接近,企业 AI 的效果差异越来越多地取决于:你给模型的上下文质量有多高。同样的模型,接入了组织级上下文图谱的 AI,和只做了基础 RAG 的 AI,输出质量可能天差地别。
2)AI Agent 爆发,对 Context Graph 上下文的要求量级跃升
Agent 不只是回答问题,它需要理解当前状态、做出判断、执行动作、追踪后果。这意味着 Agent 需要的不是”相关文档片段”,而是一个活的组织上下文:谁在负责、什么阶段、哪些依赖、什么约束、历史上类似情况怎么处理。
传统 RAG 架构很难提供这种结构化的、多维度的、实时的上下文。RAG 红利见顶,Agent 需要“组织记忆”
3)技术栈成熟,建设门槛下降
图数据库(Neo4j、Amazon Neptune、TigerGraph)、LLM 驱动的实体/关系抽取、向量+图混合检索、流处理与 CDC(变更数据捕获)等技术的成熟,使得构建企业级 Context Graph 的难度和成本显著下降。
企业实践调研:谁在建 Context Graph
目前行业中,多家企业和平台正在以不同路径构建自己的 Context Graph 体系。按其聚焦的主对象类型和应用场景,大致可以分为以下几类。

协作与生产力套件型实践的特点是:基于已有的办公/协作产品矩阵,将分散在邮件、文档、日历、聊天、工单等系统中的工作对象和行为数据,统一建模为组织级上下文图谱。
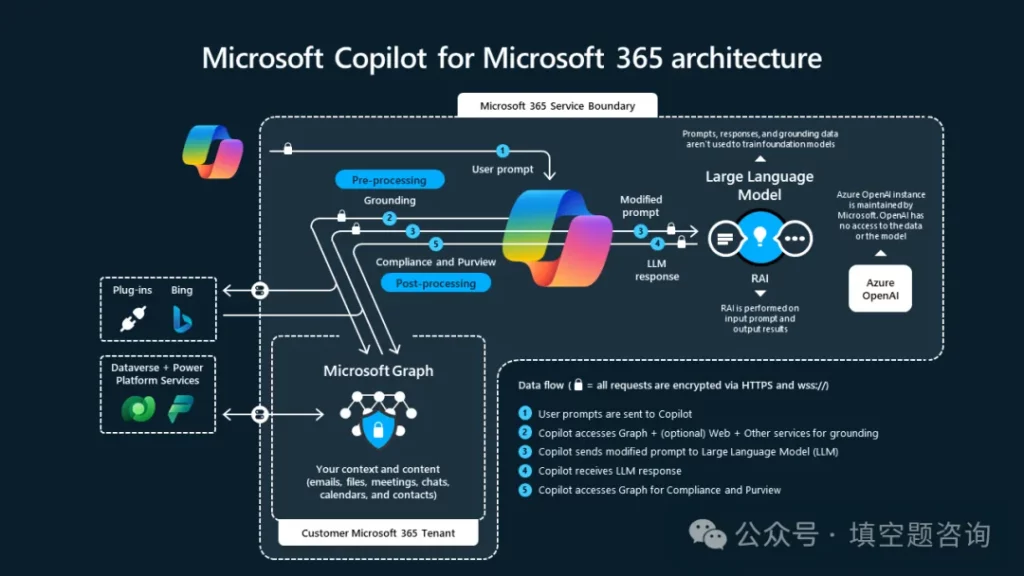
1)Microsoft:Graph + Semantic Index + Copilot
Microsoft 是企业 Context Graph 的最早实践者之一,只是过去不以这个名称被广泛认知。
Microsoft Graph 统一了 Office 365 生态中的核心对象——邮件、Teams 消息、Calendar 事件、SharePoint 文档、OneDrive 文件、Meeting 记录、用户身份与组织层级。Semantic Index 在此基础上构建了语义索引层,为 Copilot 提供 grounding(接地)能力。
Copilot 出现后,行业才真正意识到:Microsoft Graph 不是一个 API 层,而是微软最核心的 AI 资产——它决定了 Copilot 能理解多少”你的组织”。
微软的优势在于覆盖面广(几乎所有办公场景)、身份体系成熟(Azure AD)、企业渗透率高。其局限在于:Graph 更偏”沟通与文档上下文”,在工程交付、incident 管理、目标追踪等深度工作流上的建模相对较轻。
2)Google:Workspace + Gemini Grounding
Google 的路径与微软类似:通过 Workspace 生态(Docs、Gmail、Meet、Calendar、Drive)构建组织上下文,并通过 Gemini 的 Workspace grounding、Cloud Search、Vertex AI Search 等能力将上下文注入 AI。
Google 的优势在于搜索与语义理解的技术底蕴深厚,Gemini 与 Workspace 的集成也在快速推进。
其相对局限同样明显:Workspace 覆盖的主要是文档与沟通场景,在项目管理、工单、代码、incident 等工作流级别的上下文建模上,深度不如专注 work management 的平台。

3)Atlassian:Teamwork Graph——把企业 AI 拉回”组织现实”
Atlassian 的 Teamwork Graph 是一个值得重点关注的样本,因为它的建模对象和微软、Google 有显著差异。Teamwork Graph 做了几件事:
- 统一组织里的工作对象。 节点不只是文档和消息,而是包括:Jira issue、Confluence page、Slack message、GitHub PR、Loom 视频、Google Docs、用户、Team、Goal、Decision、Incident、Service Request 等。
- 建立对象之间的关系。 边包括:谁负责、谁审批、谁讨论过、哪个文档关联哪个任务、哪次 incident 影响哪个项目、哪个目标依赖哪些工作、哪段代码关联哪个 ticket。
- 学习团队行为与协作模式。 不只是静态关系,还包括协作频率、沟通路径、决策参与等动态行为数据。
- 为 AI 和 Agent 提供实时上下文。 通过 Teamwork Graph API、 等接入方式,将图谱暴露给 Agent。
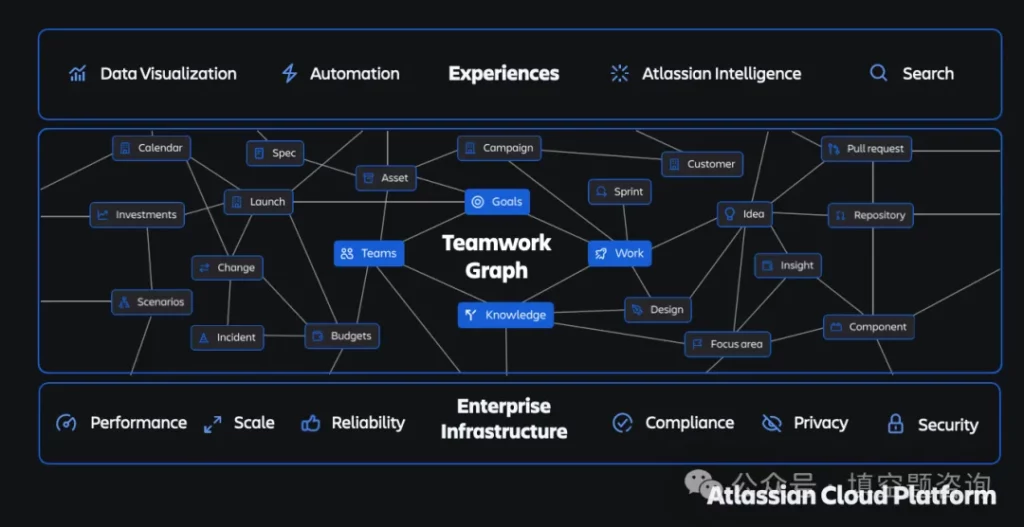
Atlassian 官方直接将 Teamwork Graph 定义为:
“The context engine behind your AI”
Atlassian 在这个赛道上的独特优势,在于它的”组织现实”覆盖深度。
因为它天然拥有 Jira(工作管理)+ Confluence(知识)+ JSM(服务管理)+ Bitbucket(代码)+ Loom(异步沟通)这样的产品矩阵,已经覆盖了 work、knowledge、service、engineering、collaboration 五个维度。这意味着它能建模的不只是”人们在聊什么”或”文档里写了什么”,而是组织真正在做什么——谁在负责什么任务、处于什么阶段、阻塞在哪里、关联哪些代码变更、影响哪些服务。
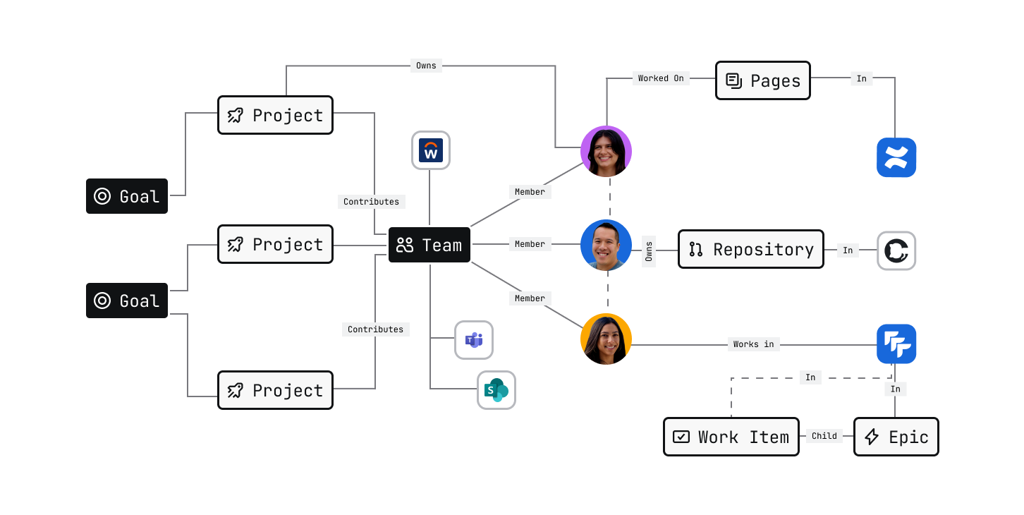
这是”把企业 AI 拉回组织现实”的关键:AI 的推理不是基于碎片化的文本,而是基于组织运作的真实结构。
从 Team ’26 发布的信息看,Teamwork Graph 已经在从数据层向 Agent Runtime Context Layer(Agent 运行时上下文层)演化,TWG CLI、MCP 接入、Cross-agent context、Graph-aware orchestration 等能力的推出,说明它的定位已经不只是”存数据的图”,而是正在成为 Agent 编排的上下文操作系统。
这也是为什么 Atlassian 近期一直在强调 System of Work、Teamwork Graph、Rovo、Agentic Collaboration,而不是单纯做一个 Copilot。
技术演进的时间线
当前行业正处于 Context Graph → Agent Runtime Infrastructure 的转折点。多家企业的实践——无论是 Microsoft Graph、Atlassian Teamwork Graph、Salesforce Data Cloud 还是 Glean 的 Context Layer——都在从”静态的数据图谱”向”Agent 可消费的运行时上下文”演化。

洞察
过去十年,SaaS 的竞争核心是功能——谁的工单系统更灵活、谁的文档编辑器更好用。
现在,竞争焦点正在迁移到:谁掌握了更高质量的组织上下文。
因为 AI Agent 的效果,在模型能力趋同之后,很可能主要取决于 Context Quality(上下文质量),而不是 Model Quality(模型质量)。
LLM 正在商品化,但企业级上下文图谱不会。
这也是为什么我们看到:Microsoft 在加倍投入 Graph + Semantic Index,Atlassian 在全面押注 Teamwork Graph + Rovo + Agentic Collaboration,Salesforce 在围绕 Data Cloud 构建 Agentforce,Glean 在从搜索层升级为 Context Layer。
方向各异,但底层逻辑一致:在 Agent 时代,谁拥有组织的上下文,谁就拥有 AI 的控制权。
Comments are closed