
本系列已发布文章:
AI 时代软件研发范式全景:7大权威机构如何定义下一代 SDLC
2026 从 SDLC 到 AIDLC:5 个实操方法实现研发效能跃迁
Atlassian 官宣 AI-Native 研发新范式:从“编程助手”进化为“数字队友”
本文不再重复解释“ AI-Native SDLC 是什么”,而是进一步回答一个更落地的问题:Atlassian 提出的五大结构性转变(Five Structural Shifts),放到真实研发团队中,究竟会怎样改变需求、开发、测试、交付、知识管理和治理方式?
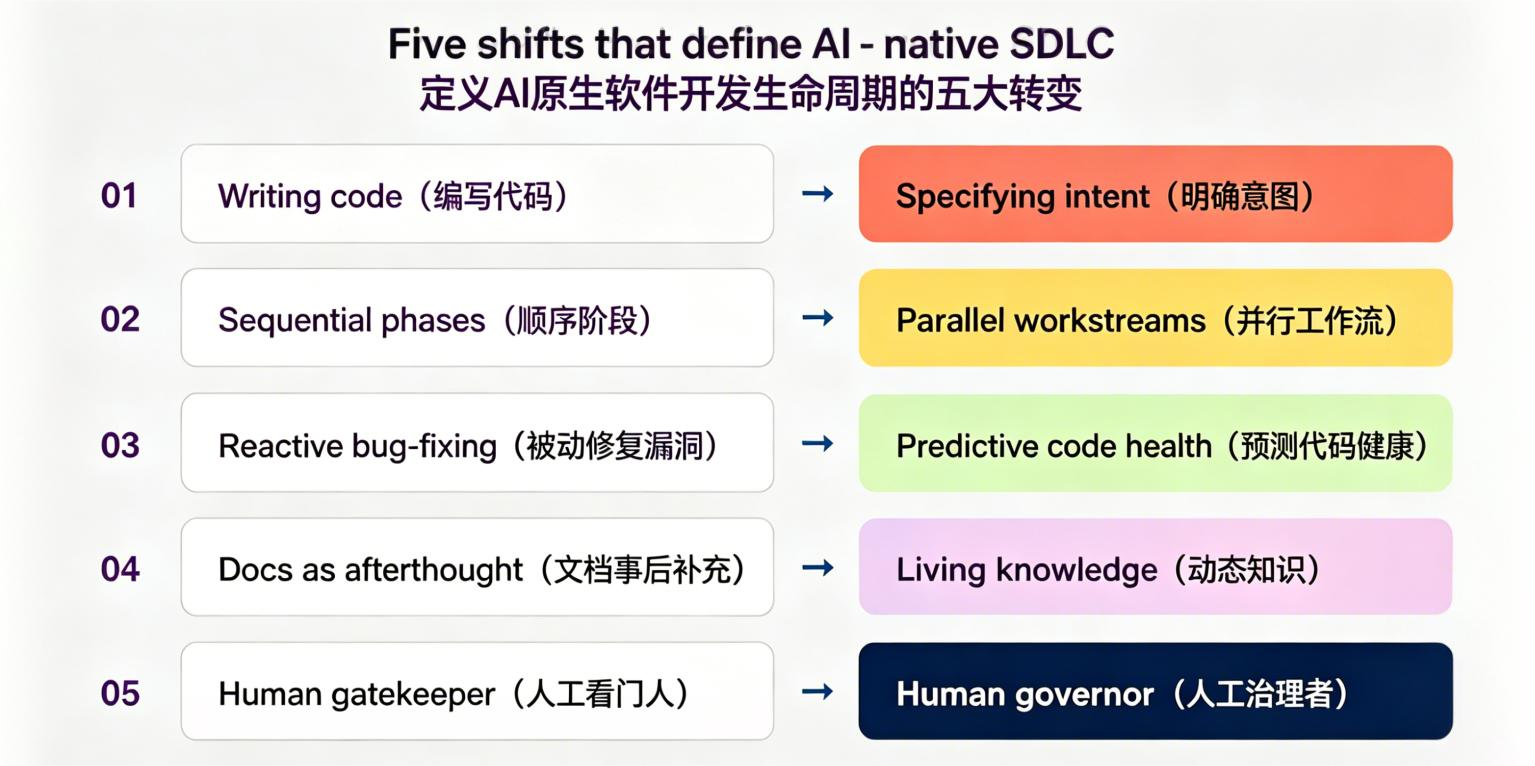
Atlassian 将传统 SDLC 到 AI-Native SDLC 的变化概括为五个结构性转变:从手写代码到指定意图,从串行阶段到并行工作流,从被动修 Bug 到预测性代码健康,从事后文档到活知识,从人工守门人到人工治理者。
我们在客户项目中的观察是:这五个 Shift 不是五句漂亮的趋势判断,而是一张非常实用的流程改造地图。它提醒团队,AI 原生研发的关键不只是“代码生成更快”,而是研发组织的运行逻辑正在发生系统性调整:人更聚焦意图定义、上下文补齐、规则设定、风险判断和持续治理;AI 则在明确边界内承担更多生成、分析、校验和反馈工作。
一、从“理解概念”走向“流程改造”
在前面三篇文章中,我们已经分别讨论了 AIDLC 的演进逻辑、七大权威机构的共识,以及 Atlassian Software Collection 的产品化路径。实际进入客户场景后,问题会变得更具体:团队并不是不知道 AI 很重要,而是不知道应该先改哪一段流程、把人机边界划在哪里、如何避免 AI 产出带来新的风险。所以,这篇文章是对 Atlassian Five Structural Shifts 的进一步实操展开。结合填空题咨询在客户项目中看到的真实阻力,把这五个 Shift 翻译成企业可以落地讨论的流程改造清单。
二、Atlassian 五大结构性转变:从趋势判断到流程实践
填空题咨询观察:在与众多企业沟通 AIDLC 转型时,我们发现最大的误区是“工具替代人”。实际上,Atlassian 提出的这五个 Shift 本质上是组织上下文的重构。以下是我们结合本土研发场景,对这五个转变的实操。
01 从:Writing code(人工手写代码)→ Specifying intent(定义业务意图)
Atlassian 的判断:AI-Native SDLC 中,开发者的核心动作会从“手写实现代码”转向“指定业务意图”。代码仍然重要,但代码不再是协作的起点,清晰的 Intent、Spec、验收标准和上下文才是起点。实操案例说明:以“支付风控规则调整”为例,传统做法是产品写需求、开发理解后手工改接口、QA 再补测试。AI 原生做法应先在 Jira 中写清楚业务目标、触发条件、限额规则、异常处理、审计要求和禁止绕过的安全约束,再让 Rovo Dev 或其他编码智能体基于这些信息生成实现草案、测试用例和 PR 描述。团队能力变化:开发者的价值不再只是“写得快”,而是能否把模糊需求翻译成 AI 可执行的结构化意图。产品、架构师和 Tech Lead 也需要共同维护高质量的 Spec,而不是把需求理解全部留给开发阶段消化。落地提醒:Spec 不是越长越好,而是要覆盖目标、约束、例外、不可做事项和验收方式。对于 AI 来说,缺失的上下文不会自动消失,只会变成错误实现、错误测试或错误假设。
Tips:过去我们会要求开发同学先理解需求,再手工补齐接口、领域模型、测试用例。现在更合适的做法,是先写清楚“实时风控支付服务”的业务意图,例如单笔限额、异常熔断、灰度策略、审计要求和不可绕过的安全规则,再让 AI 基于这些上下文生成实现草案,最后由工程师审查架构与风险。
02 从:Sequential phases(串行阶段开发)→ Parallel workstreams(多链路并行协同)
Atlassian 的判断:AI-Native SDLC 会打破“需求、设计、开发、测试、发布”严格串行推进的节奏。不同角色可以围绕同一份上下文并行工作,AI 在中间承担同步、生成、补齐和提醒的角色。实操案例说明:想象一下,当产品经理在 Jira 完善需求细节时,QA 已经让 AI 基于当前的 User Story 自动生成了 80% 的测试用例,而 DevOps 已经收到了关于该变更可能引发的流水线资源预警。大家不再是“接力赛”中等待交棒的选手,而是在同一个“作战室”里,基于 Teamwork Graph 提供的统一上下文同步推进。团队能力变化:并行协同要求团队有更强的上下文管理能力。Jira、Confluence、Bitbucket 和 Pipelines 不能只是分散工具,而要通过 Teamwork Graph 形成统一的工作网络,让每个角色看到同一个事实源。落地提醒:并行不等于混乱加速。没有明确负责人、状态流转、变更记录和审查机制,AI 只会把不一致的需求、更快地扩散到代码、测试和文档中。
Tips:在试点团队中,我们通常不建议一开始就追求全自动交付,而是先选择需求拆分、测试用例生成、PR 描述生成这类高频低风险场景。这样既能让产品、研发、QA 在同一周期同步推进,也能让团队逐步建立对 AI 输出的信任。
03 从:Reactive bug-fixing(被动故障修 Bug)→ Predictive code health(预测式代码健康管控)
Atlassian 的判断:AI-Native SDLC 不应等到缺陷上线后再救火,而应通过上下文、代码关系、历史缺陷、依赖变化和流水线信号,提前判断代码健康风险。实操案例说明:当一个 PR 修改了支付、权限或数据同步链路,AI 可以自动结合历史缺陷、关联 Jira、依赖库变化、测试覆盖和 Pipelines 结果,提示“这次变更可能影响哪些服务”“是否缺少关键测试”“是否引入了高风险依赖”。团队不再只看 diff 本身,而是看这次变更对系统健康的整体影响。团队能力变化:质量团队的角色会从“后置测试执行”前移为“质量策略设计”。Tech Lead 需要定义复杂度阈值、覆盖率要求、安全基线和必须人工复核的关键路径,AI 则负责持续扫描和提醒。落地提醒:预测式代码健康不是替代测试,而是把测试、安全和质量门禁左移。对于资金、权限、隐私、核心交易链路,仍然必须设置人工审查和强制准入规则。
04 从:Docs as afterthought(文档事后补写)→ Living knowledge(活体动态知识库)
Atlassian 的判断:AI-Native SDLC 中,文档不能再是项目结束后的补充材料,而要成为持续更新、持续被引用、持续反哺 AI 的 Living Knowledge。实操案例说明:一次架构决策不应只停留在会议纪要里,而应沉淀为 Confluence 决策记录,并与 Jira Epic、相关 PR、测试结论和上线复盘建立连接。下一次类似需求出现时,AI 可以基于这些历史上下文回答“当时为什么这样设计”“哪些限制仍然有效”“哪些接口不能随意修改”。团队能力变化:知识管理不再是项目经理或文档负责人的附属工作,而是研发流程本身的一部分。每一次需求变更、代码提交、PR 讨论、测试结论和生产事故复盘,都应该成为组织上下文的一部分。落地提醒:Living Knowledge 的关键不是让 AI 自动写更多文档,而是让文档始终与真实工作流同步。否则,AI 读到的仍然是过期知识,只会更快地产生错误建议。
填空题咨询观察:这里的关键技术底座是Atlassian Teamwork Graph。它不仅连接了文档,还连接了“谁写了文档”、“这个文档关联了哪个 Jira 任务”以及“该任务对应的代码逻辑”。没有这个关系图谱,AI 只是在读死文字;有了它,AI 才能理解组织上下文。
05 从:Human gatekeeper(人类做全量准入守门)→ Human governor(人类做规则管控者)
Atlassian 的判断:AI-Native SDLC 中,人类不再适合充当所有细节的人工守门人,而应转向 Human Governor:定义原则、策略、风险边界和审批机制,让 AI 在规则内自动执行。实操案例说明:过去,一个资深架构师可能要逐条检查 PR 是否符合规范、是否影响关键服务、是否满足安全要求。新的做法是先把代码规范、安全基线、分支策略、合并条件和发布门禁固化为规则,由 AI 和自动化流水线执行初筛;架构师重点审查高风险变更、例外申请和策略调整。团队能力变化:管理者和架构师的核心能力会从“亲自审核每个细节”转向“设计可执行的治理系统”。这要求团队把隐性经验显性化,把口头规则产品化,把事后追责前移为事前约束。落地提醒:Human Governor 并不意味着放弃人工责任,而是把人的判断力用在高价值节点上。尤其在架构变更、数据安全、资金链路和客户影响较大的发布中,人工审批仍然是最后一道治理门禁。
“研发效能的下一层竞争不在于‘写代码的速度’,而在于‘定义意图的精度’。”
(The next frontier of developer productivity isn’t about the speed of writing code, but the precision of specifying intent.)
“不要让文档成为项目的墓志铭,要让它成为 AI 随时调用的组织大脑。”
(Stop letting documentation be the tombstone of a finished project; make it the “living brain” that AI can invoke at any moment.)
三、落地方法:先选一个高摩擦场景,跑通最小闭环
综合这五项转变,我们在客户项目中的建议是:不要一开始就把目标设成“全面 AI 自主研发”,而是先选择一个高摩擦、可度量、风险可控的场景作为试点,例如 PR 周期过长、测试用例补齐困难、流水线失败排查耗时、需求说明不完整等。一个可执行的最小闭环可以这样设计:先用 Confluence 和 Jira 写清楚业务背景与验收标准,再让 AI 生成实现草案、测试用例和 PR 描述;随后通过 Bitbucket、Pipelines 和人工 Review Gate 完成质量校验;最后用 DX 或团队指标跟踪 PR 周期、缺陷率、回滚率、评审耗时和人工干预频率。
实践总结:AIDLC 的核心不是让 AI 替代研发团队,而是让团队把“上下文、规则、门禁和度量”建设得足够清楚,使 AI 能在安全边界内承担更多执行工作。真正的竞争力,也从单点工具使用,转向组织级上下文工程能力。
四、写在最后
如果说前面三篇文章分别回答了“为什么 SDLC 要走向 AIDLC”,“行业权威机构如何定义新范式”,“Atlassian 给出了怎样的产品化路径”,那么这篇实践总结案例想补上的,是最容易被忽略的一步:团队应该如何把这些概念翻译成日常工作方式。我们的结论很简单:从今天开始,先把一个需求写成更好的 Spec,把一个 PR 评审变成更明确的质量门禁,把一份文档变成可被 AI 调用的活知识。AIDLC 不是一次性切换,而是一系列小闭环的持续进化。 研发效能的提升不是一道选择题,而是一道需要你自己定义答案的“填空题”。💡想要开启你的 AIDLC 转型?[预约演示]:看 Atlassian Rovo 与 Teamwork Graph 如何在真实 Jira 环境中拆解业务意图。[申请诊断]:联系填空题咨询专家,定制你的最小闭环(MVP)试点方案。👉[点击原文联系我们]
我们不是任何方法论的信徒,但从中受益匪浅。
知识不能让你成功,但是能减少过程中的“不利因素”。
点击下方卡片关注我们
让创新尝试更简单
Atlassian 官宣 AI-Native 研发新范式:从“编程助手”进化为“数字队友”
2026 从 SDLC 到 AIDLC:5 个实操方法实现研发效能跃迁
AI 时代软件研发范式全景:7大权威机构如何定义下一代 SDLC
Microsoft、Google、Atlassian:企业 AI 上下文之争,你该押注谁?
如果您想咨询细节,请点击提交需求 (我们将尽快联系您)。
隶属 杭州填空题科技有限公司
Comments are closed